My Motivations for Starting a Blog
Hello world!
My name is Sebastian Schweer, and I am a Data Scientist. This job description is increasingly popular, but it is notoriously difficult to describe precisely, what that entails. Let me show you one of my favourite definitions:
Source.
My job requires me to spend a lot of time each day writing code in varying languages, mostly R but also Python and SAS. This inevitably leads me to spend a lot of time thinking about both code as well as the process of programming itself. The major question is, as always, “How do you ensure, that your product is of the best quality?”. Recently, I stumbled upon1 a incredibly concise diagram:
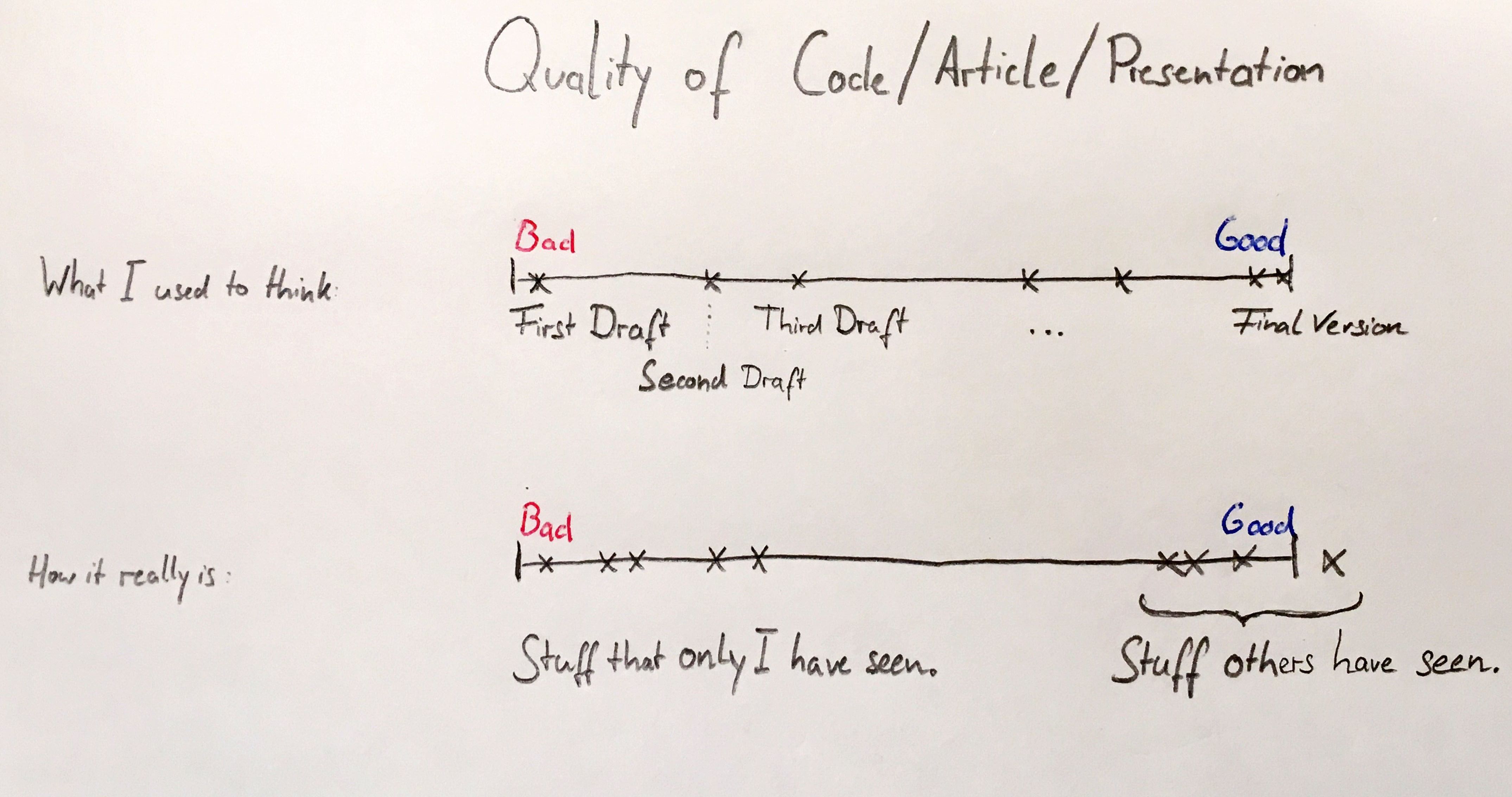
The importance of collaboration
I believe this is an astute observations, and I find its reflections in many daily situations including (but not limited to) producing code or data analyses. More precisely, I identified these 3 consequences of writing code with the intent of publicizing:
- Tested: Nobody wants to publish content that only works once or only works on a certain local machine. Thus, any project up for publication automatically gets tested and tried much more meticuously.
- Modular: It is much easier to explain and distribute several single clear ideas than one larger, vague idea. Hence, publication leads to more modular code, creating a more flexible and adaptive code base.
- Documented: It doesn’t suffice if you as the author understand what the function with non-descriptive names such as
fn_011_v3does, that should be apparent from the name or at least from the documentation. The onus of understanding the code is transferred from the mind of the author to the body of the code.
All of these characteristics increase the maturity and quality of the code. Since I am obviously interested in producing high quality work, I started this blog in order to have a public outlet for all my private little programming projects.
The scope of these projects will vary wildly, I am sure, since the inspiration are heterogeneous. For instance, the first three posts have three different “sponsors”:
- I wrote Setting up an RStudio instance on AWS with the audience of my father in mind, since he showed such an interest in my explanations of the topic over the Christmas break,
- I wrote (or rather ‘will write’) the post A benchmark for dplyr vs. dbplyr for my sister-in-law, since she asked me about the topic and I didn’t know anything about it at the time,
- and for the present article, or rather statement, I had my former employer in mind, a great fan of simple but concise diagrams depicting deep thoughts.
I appreciate any remarks or comments on anything that I write, and I wish you lots of entertainment perusing my site.
I can’t find the original source anymore, I have spent a long time going through my Twitter feed. If anyone recognizes the slide and especially the author, I would be incredibly thankful for the information and would gladly update the source information here.↩
